Draw Decision Tree Online From Data Machine Learning
Decision Trees — How to draw them on paper

This article will discuss:
- Decision Trees — A famous classification algorithm in supervised machine learning
- The basics behind decision trees and how to develop one without a computer
What you are already supposed to know:
- Basics of statistics and probability
When it comes to classification problems in machine learning, algorithms like Logistic Regression, Discriminant Analysis, etc. are the ones that come into one's mind. There is another type of classification algorithm which is highly intuitive, easy to interpret and understand called the Decision Tree algorithm. The tree-based models can be used for both regression and classification but we will discuss only the case of classification here. A typical decision tree is drawn below to make you familiar with the concept:
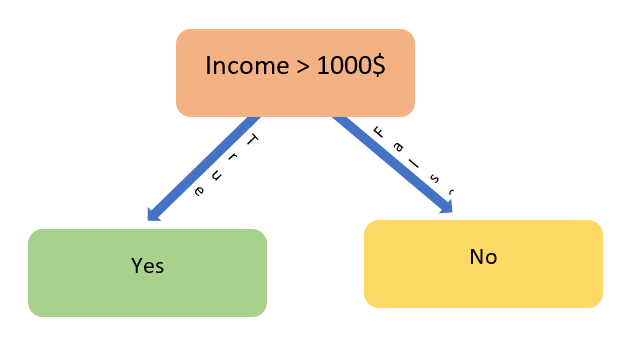
The above decision tree shows the chances of finding a TV in a random household. As it can be easily read, the above tree suggests that if a person has a monthly income of more than 1000$ he will be having a TV at home and else otherwise. The above tree can be seen as the visual representation of the model developed from the below data. The " Monthly income" is a predictor variable and " TV at home" is a response variable here.
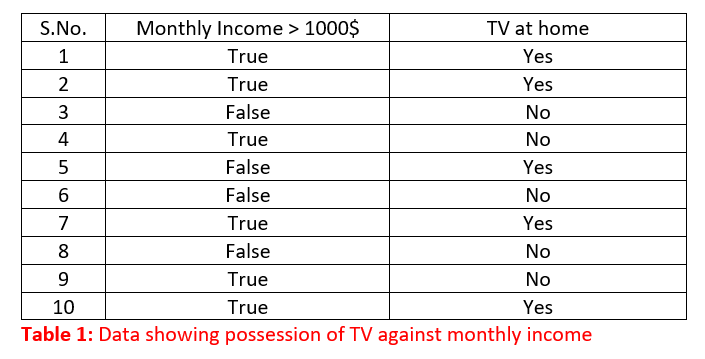
Let's have a dumb approach towards the above data set. There are 10 data points in total and under the monthly income column, there are 6 True values and 4 False values. Now, let's analyze only the True values first. Among the 6 True values, 4 have Yes against the corresponding row under TV at home column while 2 have No against them. The rows under consideration are shown below:
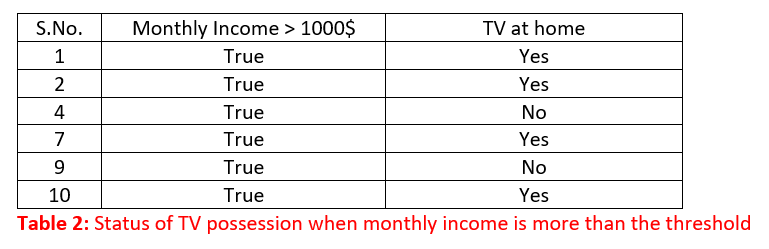
The above data is said to be impure as there are the mixed response values (4 Yes & 2 No) against the same predictor value of True. An ideal data set for us would have been the one having only Yes against True values or No against the True values. In such a scenario the decision making would have been quite easy and straight forward. But since the response is mixed or impure, we won't be making any conclusions here, let's analyze the other value under monthly income column:

The above data set is impure too, for the same predictor value of False, there is a mixed response variable value here. Since the majority of values against True is Yes and that against False is No, it means the probability of finding Yes against True is more and so is No against False and hence the decision tree is made as shown above. The single predictor variable model is as easy as it appears. Things start to get complicated when more than one variable is involved in the model. We will see that soon but let's move our focus to a term introduced above called impurity.
Impurity and its measurement
Impurity means how heterogeneous our data is. As in the above case, as already mentioned, things would have been more straight forward, if, to every True value in predictor column there was a Yes in the response column or vice versa. As in almost all practical situations, this is not the case and we usually get mixed data set. We need to find a way to measure impurity. There are already two methods there to measure the degree of impurity or heterogeneity of data:
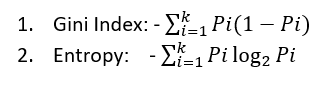
Although both of them measure impurity to the same extent and result in the development of similar models, we will only consider entropy here. Let's discuss the various parameters in the entropy equation. Pi is the probability of ith class in the target/response variable e.g. if the target variable has classes distributed as [0,0,1,0,1,1,0,1,1], P(0) = 4/9 and P(1) = 5/9. Applying the concept to Table 1, we will be having P(Yes) = 5/10 and P(No) = 5/10. Moving to another parameter, notice the use of base 2 logarithmic function. If you want to know more about the use of base 2 in the equation, you should read this .
Now having the equation of Entropy at our hand, lets first calculate the entropy of overall data (Table 1). Since the Yes values are present 5 times and No values are present 5 times too, we have:
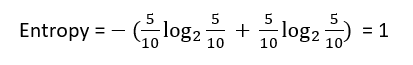
Let's now calculate the entropy of the data below the True split (Table 2). The target variable here is " TV at home" having two classes into it " Yes" and " No". The Yes value is present 4 times and No is present 2 times.
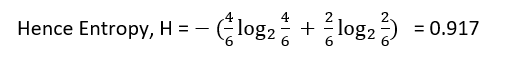
Suppose the target variable had only one class into it (completely pure), then the entropy would have been:
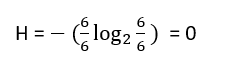
This shows the data set having complete homogeneity into it has entropy = 0 and it would be easy to show that the completely impure data set (each class observation present in equal number) has the entropy of 1.
Likewise, the entropy of the data under the False split would be:
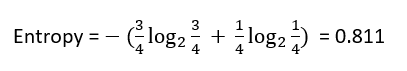
The net entropy of the data after the Income variable is introduced can be calculated by taking the weighted average of the two entropy values under its splits
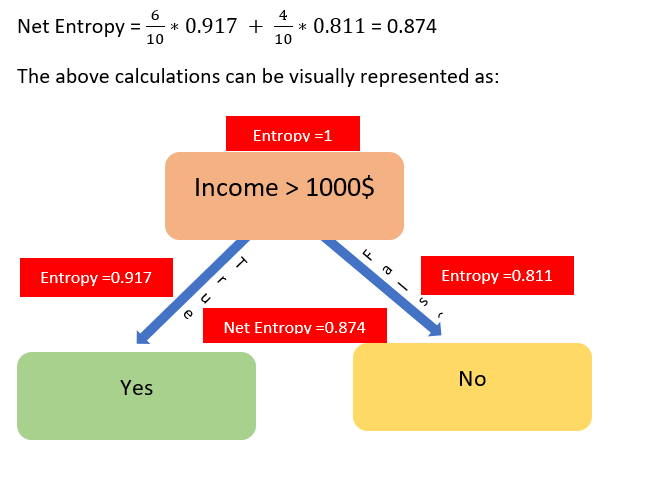
The flow of entropy needs to be clearly understood. Initially, it was 1, the True split reduced it to 0.917 and False split reduced it to 0.811. The net reduction by the Income variable is 0.874. This is what we expect, the reduction in entropy (impurity of heterogeneity) by the introduction of variables. The total reduction is 1–0.874 = 0.126. This number (0.126) is called information gain and is a very important parameter in decision tree model development.
This is how the degree of impurity is calculated through entropy calculation. Now let's apply this concept in the model development.
Model Development
Now in addition to the above information of guessing TV possession through monthly income, suppose it was later bought to our notice that not only monthly income but there is another variable which influences the result and the variable is the location of a person, whether he lives in an urban area or rural. Let the updated data-set be as shown below:
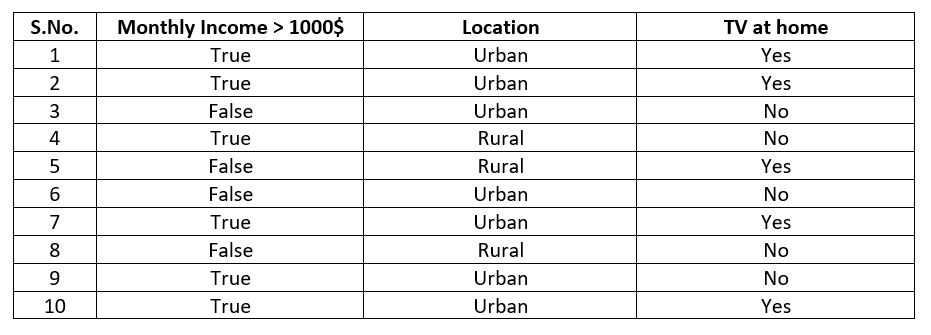
The above data-set presents a dilemma for us for whatever we know so far. The dilemma is: whether to start our decision tree with income predictor or location predictor. We will try to resolve this dilemma through entropy calculation for both the predictors but let's present the location variable against the target variable in segregated form as below:
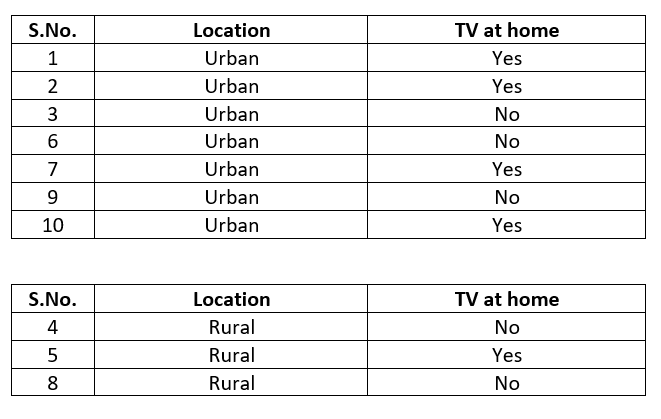
Let's calculate the entropy under both the income & location variable separately:
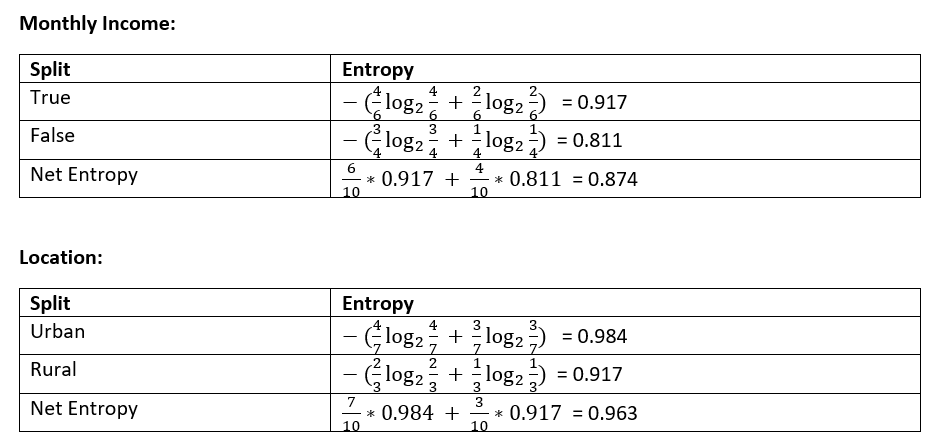
As you can see, entropy down the monthly income is lower than that of location variable, we can say that the heterogeneity of the system is reduced more by monthly income variable than the location variable and the information gain is 1–0.874 = 0.126. Going by the information gain criteria, our decision tree should start with the monthly income variable again as shown below:
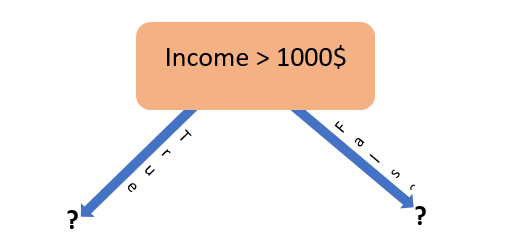
Although we have found out our first variable, we can't just finish it up here. We are having another variable at our disposal, which can increase the efficiency of our model. Now the next question is where to place that, down the tree. We have two possible places for location variable & both will pass the different data values to it & hence different information gain. We will place it there, where the information gain in maximum. Let's calculate and find it out.
The column for True values is shown below:
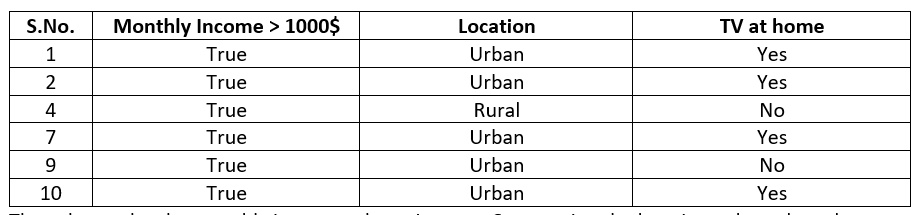
The value under the monthly income column is the same. Segregating the location column based on column values, we will get the tables as shown:
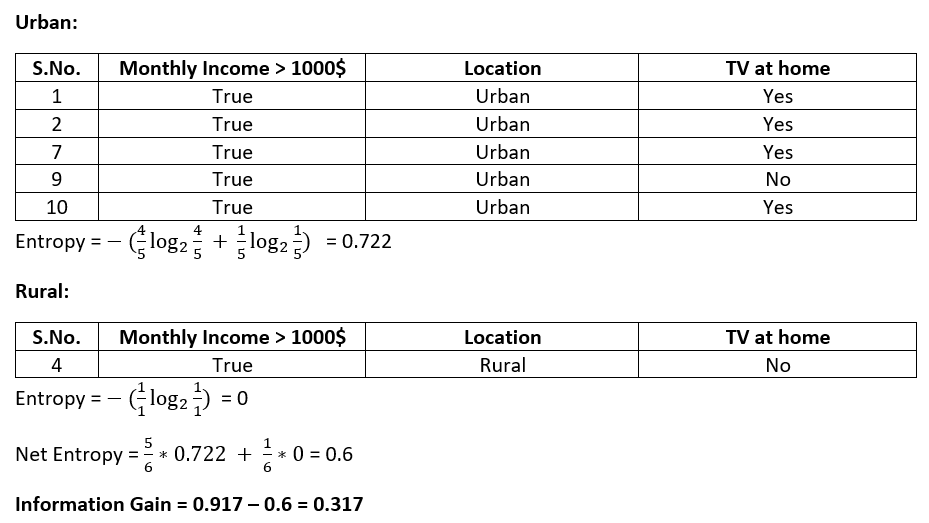
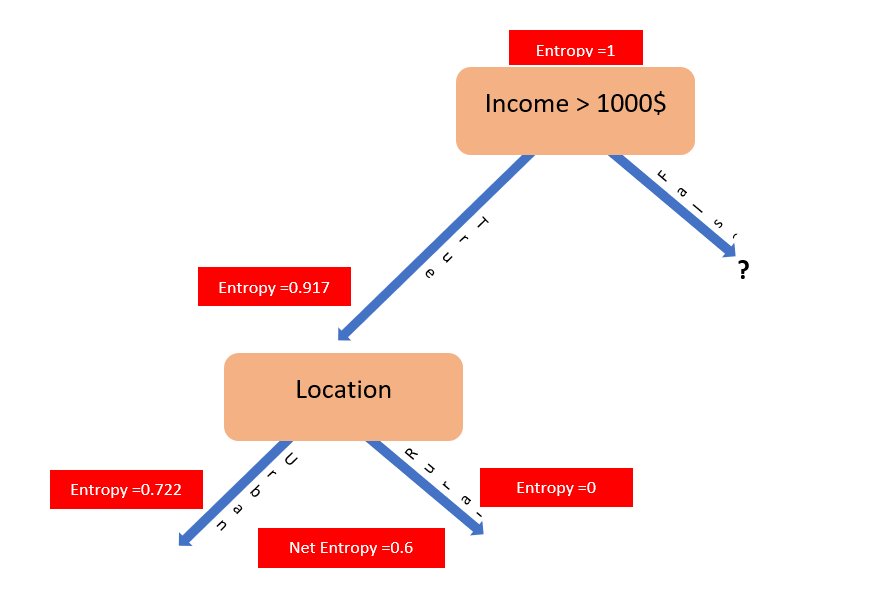
The above calculations can be visualized as shown below:
If we place the Location variable under False split, the calculations & data tables would be as:

The value under the monthly income column is the same. Segregating the location column based on column values, we will get the tables as shown:
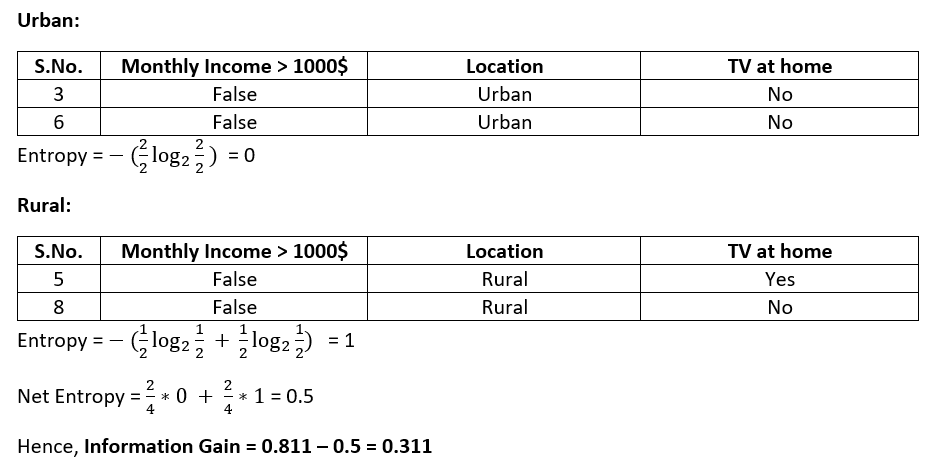
The above calculations can be visualized as under:
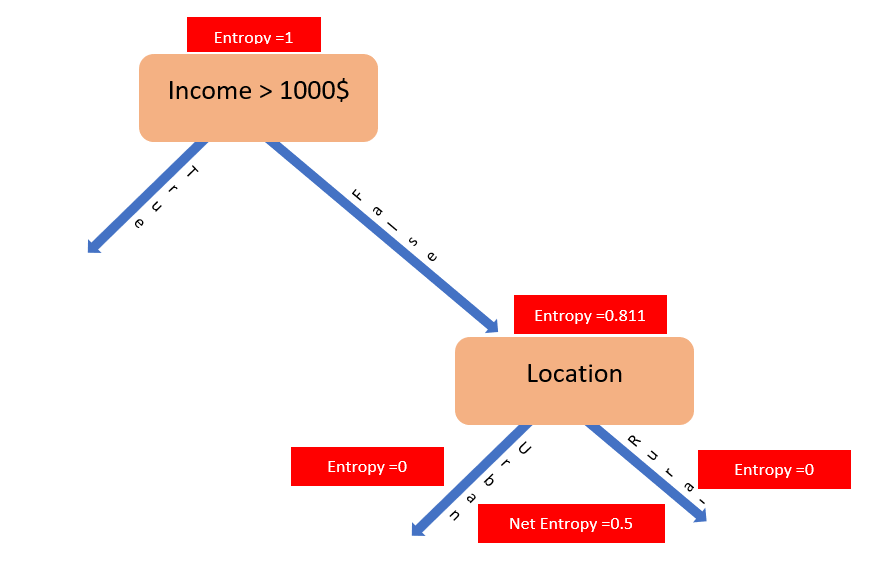
Since Information gain under False split is less than the True split, the decision tree will look like:

The Probability of finding Yes value for Urban predictor value is more than No value and hence the above arrangement.
The above tree suggests that if the income is less than 1000$ there would be no TV in the household and if the income is more than 1000$ then we have to check the location of the household, if urban, the TV can be found and else otherwise.
This is how decision trees are developed. The results by decision trees are often less accurate than that by other classification models like Logistic regression or Linear Discriminant Analysis but they are useful when the need for understanding or interpreting the system is more than that of prediction.
Now that you have understood the concept of developing a decision tree let's understand the various terms used in the decision trees.
Node: A node is something that represents a variable in the decision tree e.g. income and location are the nodes.
Root Node: The Node from where the tree starts e.g. income in the above decision tree.
Leaf Nodes: The bottom-most nodes, where the value of the target variable is decided e.g. location is the leaf node in the above tree.
Splitting: The process of splitting a node into two or more sub-nodes is called splitting
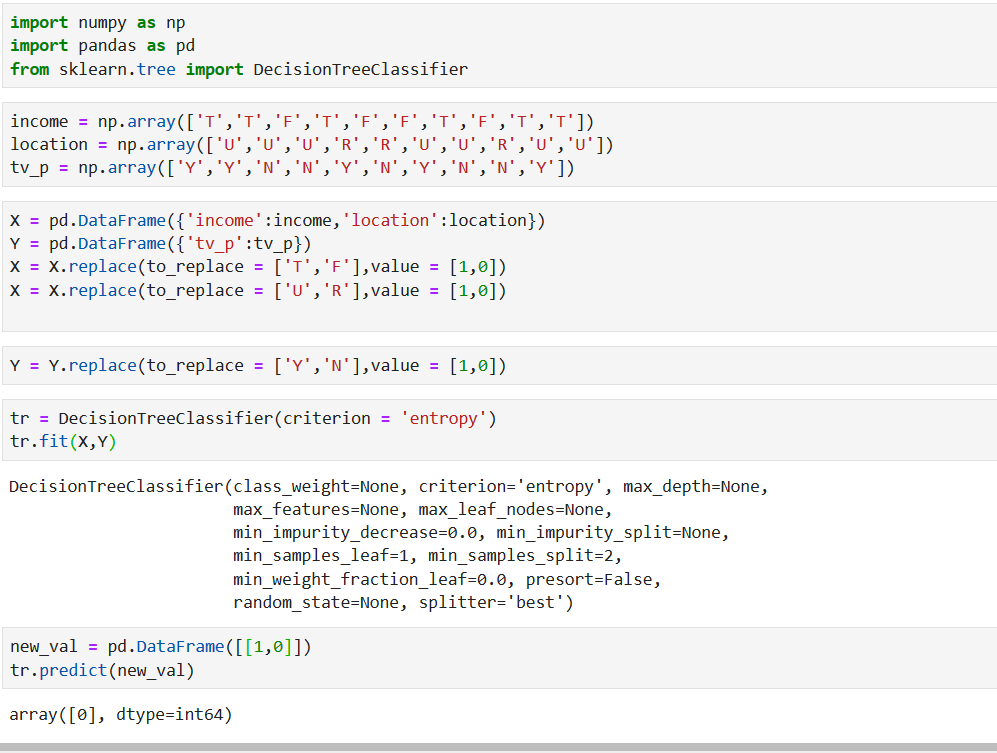
The Python code for whatever we have done so far is shown below:
If you find the above concept interesting, you can further read the below-mentioned topics:
- Random Forest
- Bagging
- Boosting
Thanks,
Have a good time :)
For any query regarding the article you can reach me out on LinkedIn
carrollouldives49.blogspot.com
Source: https://towardsdatascience.com/decision-trees-how-to-draw-them-on-paper-e2597af497f0
0 Response to "Draw Decision Tree Online From Data Machine Learning"
Post a Comment